トレンドとは何か?
- そもそもトレンドとは何か。
- ここでは単調非減少あるいは単調非増加列としてトレンドを定義する。
import pandas as pd import numpy as np from scipy import stats from matplotlib import pylab as plt import seaborn as sns sns.set() sns.set_style("darkgrid") import math import pymc3 as pm fx_data = pd.read_csv("/Users/ユーザー名/Documents/FX/foreign_exchange_historical_data/USDJPY/USDJPY_DAY.csv")#データの読み込み #pandasの計算は遅いので、全てnumpy配列に変換 opening = np.array(fx_data["opening"])#始値 high = np.array(fx_data["high"])#高値 low = np.array(fx_data["low"])#低音 closing = np.array(fx_data["closing"])#終値 trend = 1#いくつに分割されるのか調べるので、最初から0ではなく1としておく up_trend = 0 down_trend = 0 prev = closing[0] state = "na" for i in range(1, len(closing)): prev = closing[i-1] current = closing[i] if current > prev: if state == "dec": trend += 1 down_trend += 1 state = "na" else: state = "inc" elif current < prev: if state == "inc": trend += 1 up_trend += 1 state = "na" else: state = "dec"
- 結果はこちら
print(trend, up_trend, down_trend) 1117 542, 574
- 上昇トレンドと下落トレンドの比率は542:574でほぼ1:1として良い。
- また、全日数とトレンドの割合は
trend/len(closing) 0.34023758757234235
となる。これから、トレンドの平均日数の期待値は、この逆数をとって、約2.94日であることもわかる。
変動値の従う分布(python)
- 結論まで一気に。
import pandas as pd import numpy as np from scipy import stats from matplotlib import pylab as plt import seaborn as sns sns.set() sns.set_style("darkgrid") import math import pymc3 as pm fx_data = pd.read_csv("/Users/ユーザー名/Documents/FX/foreign_exchange_historical_data/USDJPY/USDJPY_DAY.csv")#データの読み込み #pandasの計算は遅いので、全てnumpy配列に変換 opening = np.array(fx_data["opening"])#始値 high = np.array(fx_data["high"])#高値 low = np.array(fx_data["low"])#低音 closing = np.array(fx_data["closing"])#終値 co = closing - opening with pm.Model() as model_t: mu = pm.Uniform("mu", min(co), max(co)) sigma = pm.Uniform("sigma", 0, 20) nu = pm.Uniform("nu", 0, 100) y = pm.StudentT("y", mu = mu, sd = sigma, nu = nu, observed = co) trace_t = pm.sample(11000) chain_t = trace_t[1000:]
- pymc3のmodelでは平均、標準偏差、自由度ともに事前分布として一様分布を指定している。また、burn inも行っている。
- 結論は以下。
pm.summary(chain_t)
mean sd hdi_3% hdi_97% mcse_mean mcse_sd ess_mean ess_sd \
mu 0.008 0.009 -0.009 0.025 0.000 0.000 14798.0 12565.0
sigma 0.421 0.010 0.403 0.439 0.000 0.000 10321.0 10314.0
nu 3.430 0.234 3.011 3.879 0.002 0.002 10575.0 10525.0
ess_bulk ess_tail r_hat
mu 14798.0 12540.0 1.0
sigma 10331.0 13017.0 1.0
nu 10656.0 12559.0 1.0
- 図は下。

- 平均、標準偏差は以前に計算した結論と矛盾しない。
- もとのヒストグラムと重ねてみる。
mu_new = chain_t["mu"].mean() sigma_new = chain_t["sigma"].mean() nu_new = chain_t["nu"].mean() x = np.linspace(min(co), max(co), 1000) y_pred = stats.t.pdf(x, loc = mu_new, scale = sigma_new, df = nu_new) #まとめて選択 plt.plot(x, y_pred, lw = 2) plt.fill_between(x, 0, y_pred, color = "skyblue", linewidth = 2, edgecolor = "skyblue", alpha = 0.6) plt.hist(co, bins = 100, histtype = "stepfilled", alpha = 0.2, density = True, color = "blue", label = "co") plt.title("Student’s T sample") plt.xlim(min(co), max(co)) plt.legend(loc="upper left") plt.savefig("/Users/ユーザー名/Desktop/img002.png", dpi = 300)

- ピークや裾での当てはまりはそれほど良くない。
上昇する月、下落する月
- 曜日によって上昇/下落の差があるか否かを以前に調査した。
- 月によって上昇/下落の差があるか否かを調査する。いつものようにLibraryをimport。
import pandas as pd import numpy as np import scipy.stats as st from matplotlib import pylab as plt import seaborn as sns sns.set() #今回は月ごとのデータで分析 fx_data = pd.read_csv("/Users/ユーザー名/Documents/FX/foreign_exchange_historical_data/USDJPY/USDJPY_MONTH.csv")#データの読み込み #pandasの計算は遅いので、全てnumpy配列に変換
- 以下一気にグラフまで
#時系列データのためdatetimeをimport import datetime from collections import defaultdict opening = np.array(fx_data["opening"])#始値 high = np.array(fx_data["high"])#高値 low = np.array(fx_data["low"])#低値 closing = np.array(fx_data["closing"])#終値 #月のデータに変換 fx_data["date"] = pd.to_datetime(fx_data["date"]) fx_data["date"].dt.month #12か月分のデータ配列を準備 month_stat = defaultdict(int) for row in fx_data.itertuples(): if row[5] - row[2] >= 0:#row[5]は終値、row[2]は始値 month_stat[row[1].month] += 1 else: month_stat[row[1].month + 12] += 1 #比率を出すためここでも空の配列を準備 month_stat_ratio = np.zeros(12) for i in range(12): month_stat_ratio[i] = month_stat[i+1]/(month_stat[i+1] + month_stat[i+13]) #χ二乗検定を行う。 df = pd.DataFrame([month_stat_ratio, [0.5]*12]) st.chi2_contingency(df, correction = False) #p = 0.9999999758455512となり、「為替の上下に月は無関係である」という帰無仮説は棄却できない。 dict = ["{0}".format(i) for i in range(1, 13)] # %%まとめて選択 plt.bar(dict, month_stat_ratio, color = "skyblue", alpha = 0.7) plt.title("usdjpy") plt.xlabel("month") plt.ylabel("increase") plt.savefig("/Users/ユーザー名/Desktop/month.png", format = "png", dpi = 300) #このようにしても同じ結果になる。 st.chisquare(month_stat_ratio, f_exp = [0.5]*12)
- グラフも。

- これを見ると1月は下落する確率が高い印象もあるが。
レバレッジ計算式
- 総資産を
、売買単位を
、売買時点での値を
、レバレッジを
とする。
であるから、レバレッジが
である。
- 証拠金維持率は総資産を必要な証拠金で割って
となる。
- ここで値が
に変化すると、資産は
となる。必要な証拠金は
である。この時点での証拠金維持率は
となる。
- 例えば、10単位の買いポジションの場合、資産が50万円、売買時点でドル円が100円だったとする。これが102円に値上がりすると、証拠金維持率は
である。
- 逆に、98円に値下がりすると、証拠金維持率は
となってしまう。
- 証拠金維持率が100%以下になるとロスカットされる場合、
を解いて、
でなければならない。
- 一般にレバレッジをlとすると、この式は
となる。
- 売りポジションの場合は、
となる。
連続して上昇/下落した翌日の挙動
- 前回の記事で連続して上昇、あるいは下落する日数を調べた。
- そこで自然に、「連続して3日上昇した翌日は下落するのか?」、あるいは「連続して5日下落した翌日は(流石に)上昇するだろう」といった疑問が湧く。
- こちらの記事では、上昇と下落の割合は1596/3249 = 0.49108170310701954であった。約1/2であり、ドル円の上昇と下落がランダムに決定されていることを示唆している。
- ここで求める確率は、「n日連続上昇している時」(A)に、「翌日上昇する確率」(B)である。
- 仮にドル円の上昇/下落がランダムであれば、n日連続で上昇していようがいまいが、翌日上昇/下落する確率は1/2であろう。例えば、3日連続で上昇する確率は1/8となるし、4日連続で上昇する確率は1/16となる。
- 次の図は全体の中で、n日連続で上昇/下落した日数を縦軸にしたものであるが、日数が増えるにつれ、縦軸はほぼ半分になっている。
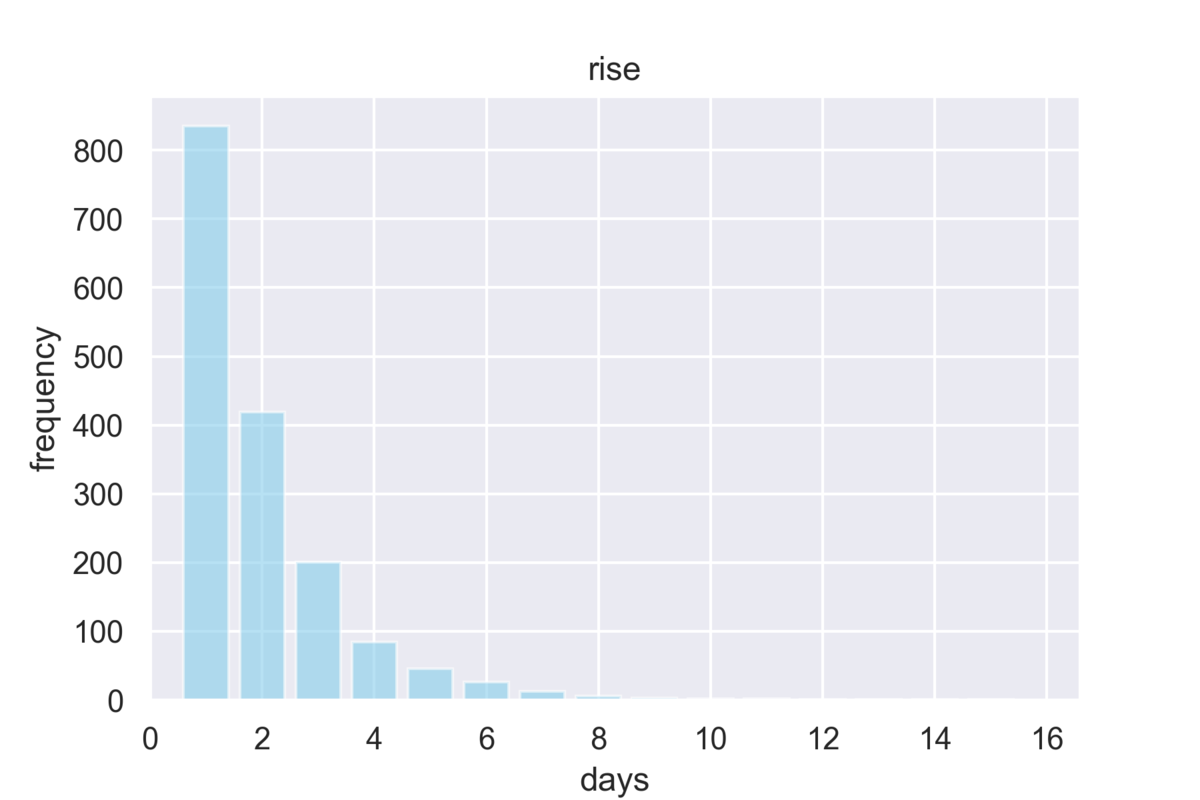
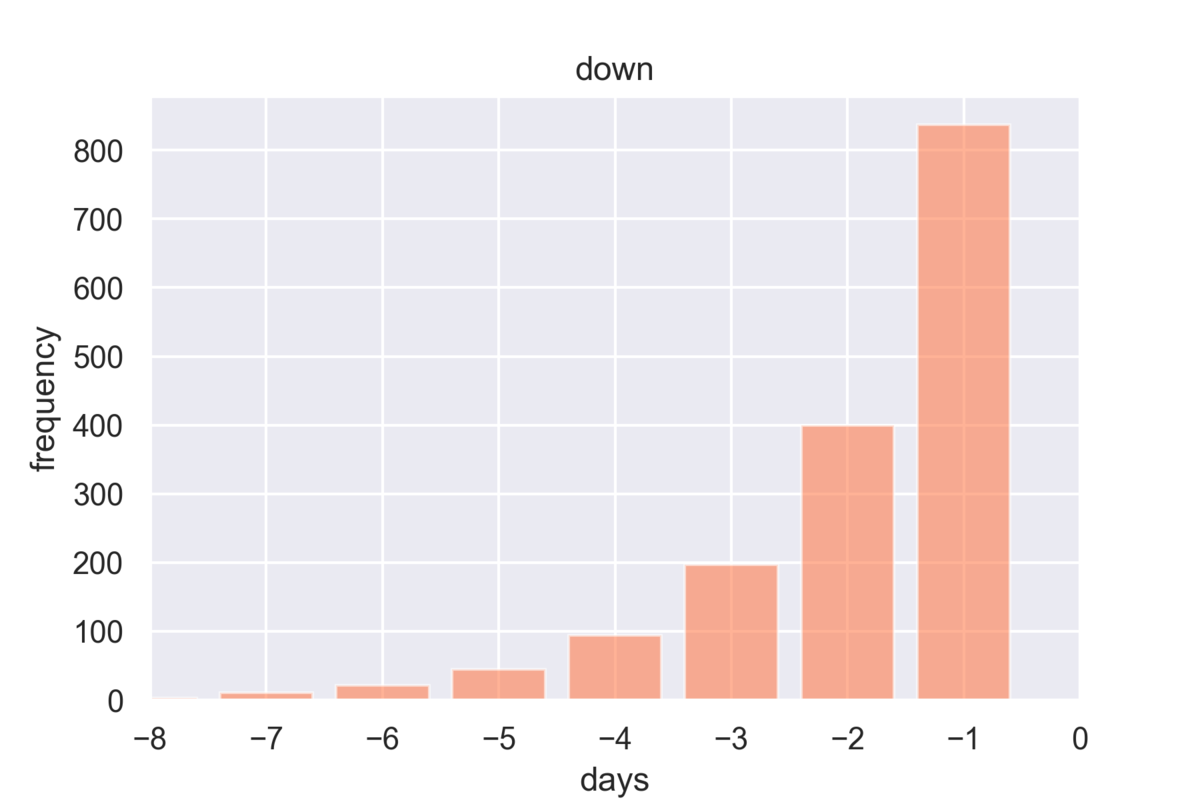
- こちらは下落の場合。
- まずはいつものようにLibraryをimportする。
import pandas as pd from pandas.plotting import autocorrelation_plot import numpy as np from scipy import stats from matplotlib import pylab as plt import seaborn as sns sns.set() import statsmodels.api as sm import heapq as hp import math fx_data = pd.read_csv("/Users/ユーザー名/Documents/FX/foreign_exchange_historical_data/USDJPY/USDJPY_DAY.csv")#データの読み込み #pandasの計算は遅いので、全てnumpy配列に変換 opening = np.array(fx_data["opening"])#始値 high = np.array(fx_data["high"])#高値 low = np.array(fx_data["low"])#低値 closing = np.array(fx_data["closing"])#終値
- n日連続して上昇/下落した時、n+1日目が上昇/下落のいずれかになるのか調査する。
days_chr = [0] * len(opening) #それぞれの日が、何日間上昇しているのか、あるいは下落しているのかを表す。 #例えば、days_chr[x] = 5とすると、xという日は5日連続で上昇していることを表す。 #days_chr[x] = -3とすると、xという日は3日連続で下落していることを表す。 m = 0 M = 0 for i in range(len(opening)): if opening[i] > closing[i]: m = 0 M += 1 elif opening[i] < closing[i]: m += 1 M = 0 days_chr[i] = -m + M from collections import Counter #Counterのimport a = Counter(days_chr)
とする。n日連続で上昇して、翌日も上昇する確率は、
a[n+1]/a[n]
として良い。
from collections import defaultdict days_prob_pos = defaultdict(int) for j in range(1, 15): days_prob_pos[j] = a[j+1]/a[j]
- 計算すると
defaultdict(int, {1: 0.5017964071856288, 2: 0.4797136038186158, 3: 0.417910447761194, 4: 0.5476190476190477, 5: 0.5652173913043478, 6: 0.5, 7: 0.46153846153846156, 8: 0.5, 9: 0.6666666666666666, 10: 1.0, 11: 0.5, 12: 1.0, 13: 1.0, 14: 1.0})
- 図示すると次のようになる。

- 解釈が重要である。1日上昇した次の日はほぼ1/2の確率で上昇する。2日連続した時も同様であるが、確率は0.479となり、多少下落の確率が高くなる。
- 3日目が重要で、3日連続で上昇した時は、4日目に上昇する確率は約0.42である。逆にいうと、6割程度下落している。
- また、4日連続、5日連続で上昇した時は、その翌日は上昇する確率の方が高い。8日目以降はサンプルが少ないので、あまり重要ではない。
- 下落の場合はどうだろう。
days_prob_neg = defaultdict(int) for k in range(-8, -1): days_prob_neg[k] = a[k]/a[k+1]
defaultdict(int, {-8: 0.2727272727272727, -7: 0.5238095238095238, -6: 0.4666666666666667, -5: 0.4787234042553192, -4: 0.47715736040609136, -3: 0.4925, -2: 0.4778972520908005})
- 図示は以下。

- こちらはほぼ1/2で下落している。
連続上昇 or 下落
- 連続して上昇/下落する日数の最大値を求める。
import pandas as pd from pandas.plotting import autocorrelation_plot import numpy as np from scipy import stats from matplotlib import pylab as plt import seaborn as sns sns.set() import statsmodels.api as sm import heapq as hp import math fx_data = pd.read_csv("/Users/ユーザー名/Documents/FX/foreign_exchange_historical_data/USDJPY/USDJPY_DAY.csv")#データの読み込み #pandasの計算は遅いので、全てnumpy配列に変換 opening = np.array(fx_data["opening"])#始値 high = np.array(fx_data["high"])#高値 low = np.array(fx_data["low"])#低値 closing = np.array(fx_data["closing"])#終値 #連続して上昇、あるいは下落する日数の最大値を求める。 m = 0 M = 0 rise_max = 0 down_max = 0 for i in range(len(opening)): if opening[i] > closing[i]: m = 0 M += 1 rise_max = max(rise_max, M) elif opening[i] < closing[i]: m += 1 M = 0 down_max = max(down_max, m) rise_max, down_max
- 結果は以下。
15, 8
- 上昇する時は最大15日連続で上昇した。
- 下落する場合、長くても8日。
- 解析期間(2007年4月2日から2020年9月29日)
ドル円の基本要約量
import pandas as pd from pandas.plotting import autocorrelation_plot import numpy as np from scipy import stats from matplotlib import pylab as plt import seaborn as sns sns.set() import statsmodels.api as sm import heapq as hp import math fx_data = pd.read_csv("/Users/ユーザー名/Documents/FX/foreign_exchange_historical_data/USDJPY/USDJPY_DAY.csv")#データの読み込み #pandasの計算は遅いので、全てnumpy配列に変換 opening = np.array(fx_data["opening"])#始値 high = np.array(fx_data["high"])#高値 low = np.array(fx_data["low"])#低値 closing = np.array(fx_data["closing"])#終値 #平均 opening_mean = np.mean(opening) high_mean = np.mean(high) low_mean = np.mean(low) closing_mean = np.mean(closing) #標準偏差 opening_sd = np.std(opening) high_sd = np.std(high) low_sd = np.std(low) closing_sd = np.std(closing)
結果は以下。
#平均 opening, high, low, closing 102.00780350978135, 102.4274237629459, 101.5360411392405, 102.01047871116225 #標準偏差 opening, high, low, closing 13.128446697845026, 13.144156607787117, 13.101283871625002, 13.132973566366692
- その他
#最大値、最小値 max(high), min(low) 125.86, 75.57 #1日の変動の最大値、最小値 max(high-low), min(high-low) 7.929999999999993, 0.03999999999999204 #1日の変動の平均値、標準偏差 np.mean(abs(closing-opening)), np.std(abs(closing-opening)) 0.4465123705408514, 0.4547812358889767 #上昇と下降の割合 co = closing - opening len(co[co >0])/len(co) 0.49108170310701954 #有意性検定を行うほどの差は考えにくい
- 簡単にやる時は、次のようにする。
fx_data.describe()
opening high low closing
count 3249.000000 3249.000000 3249.000000 3249.000000
mean 101.057579 101.473152 100.599625 101.064289
std 12.969594 12.987922 12.946784 12.976581
min 75.760000 75.980000 75.570000 75.680000
25% 90.900000 91.300000 90.250000 90.840000
50% 104.210000 104.640000 103.690000 104.190000
75% 110.620000 110.911000 110.240000 110.630000
max 125.660000 125.860000 124.540000 125.550000
- 解析期間(2007年4月2日から2020年8月15日)